Expressions
We will examine expressions by starting with the most primitive elements of expressions and working back up to the top level.
Factors
The lowest level building block of an expressions is the factor:
|
factor
|
integer-number
|
|
|
character-code
|
|
|
floating-point-number
|
|
|
string
|
|
|
regular-expression
|
|
|
identifier
|
|
|
NULL
|
|
|
(
expression
)
|
|
|
[ array
expression-list
]
|
|
|
[ set
expression-list
]
|
|
|
[ struct
[
(
:
|
=
)
expression
,
]
assignment-list
]
|
|
|
[ class
[
(
:
|
=
)
expression
,
]
assignment-list
]
|
|
|
[ func
function-body
]
|
|
|
[ module
[
(
:
|
=
)
expression
,
]
statement...
]
|
|
|
[ identifier
user-data...
]
|
The constructs integer-number, character-code, floating-point-number, string, and regular-expression are primitive lexical elements (described above). Each is converted to its internal form and is an object of type int, int, float, string, or regexp respectively.
A factor which is an identifier is a variable reference. But its exact meaning depends upon its context within the whole expression. Variables in expressions can either be placed so that their value is being looked up, such as in:
a + 1
Or they can be placed so that their value is being set, such as in:
a = 1
Or they can be placed so that their value is being both looked up and set, as in:
a += 1
Only certain types of expression elements can have their value set. A variable is the simplest example of these. Any expression element which can have its value set is termed an lvalue because it can appear on the left hand side of an assignment (which is the simplest expression construct which requires an lvalue). Consider the following two expressions:
1 = 2 /* WRONG */
a = 2 /* OK */
The first is illegal because an integer is not an lvalue, the second is legal because a variable reference is an lvalue. Certain expression elements, such as assignment, require an operand to be an lvalue. The parser checks this.
The next factor in the list above is NULL. The keyword NULL stands for the value NULL which is the general undefined value. It has its own type, NULL. Variables which have no explicit initialisation have an initial value of NULL. Its other uses will become obvious later in this document.
Next is the construct ( expression ). The brackets serve merely to make the expression within the bracket act as a simple factor and are used for grouping, as in ordinary mathematics.
Finally we have the constructs surrounded by square brackets. These are textual descriptions of other data items; typically known as literals. For example the factor:
[array 5, 6, 7]
is an array of three items, that is, the integers 5, 6 and 7. Each of these square bracketed constructs is a textual description of a data type named by the first identifier after the starting square bracket. Six data types are built-in, with other cases handled by user defined code. An explanation most of the built-in literal forms first requires an explanation of the fundamental aggregate types.
An introduction to arrays, sets and structs
There are three fundamental aggregate types in ICI: arrays, sets, and structs. Certain properties are shared by all of these (and other types as will be seen later). The most basic property is that they are each collections of other values. The next is that they may be "indexed" to reference values within them. For example, consider the code fragment:
a = [array 5, 6, 7];
i = a[0];
The first line assigns the variable a an array of three elements. The second line assigns the variable i the value currently stored at the first element of the array. The suffixing of an expression element by an expression in square brackets is the operation of "indexing", or referring to a sub-element of an aggregate, and will be explained in more detail below.
Notice that the first element of the array has index zero. This is a fundamental property of ICI arrays.
The next ICI aggregate we will examine is the set. Sets are unordered collections of values. Elements "in" the set are used as indicies when working with the set, and the values looked up and assigned are interpreted as a booleans. Consider the following code fragment:
s = [set 200, 300, "a string"];
if (s[200])
printf("200 is in the set\n");
if (s[400])
printf("400 is in the set\n");
if (s["a string"])
printf("\"a string\" is in the set\n");
s[200] = 0;
if (s[200])
printf("200 is in the set\n");
When run, this will print:
200 is in the set
"a string" is in the set
Notice that there was no second printing of "200 is in the set" because it was removed from the set on the third last line by assigning zero to it.
Now consider structs. Structs are unordered collections of values indexed by any values. Other properties of structs will be discussed later. The typical indicies of structs are strings. For this reason notational shortcuts exist for indexing structures by simple strings. Also, because each element of a struct is actually an index and value pair, the syntax of a struct literal is slightly different from the arrays and sets seen above. Consider the following code fragment:
s = [struct a = 123, b = 456, xxx = "a string"];
printf("s[\"a\"] = %d\n", s["a"]);
printf("s.a = %d\n", s.a);
printf("s.xxx = \"%s\"\n", s.xxx);
Will print:
s["a"] = 123
s.a = 123
s.xxx = "a string"
Notice that on the second line the structure was indexed by the string "a", but that the assignment on line 1 in the struct literal did not have quotes around the a. This is part of the notational shortcut which will be discussed further, below. Also notice the use of s.a in place of s["a"] on line 3. This is a similar shortcut, also discussed below.
Built-in literal factors
The built-in literals factors, which in summary are:
|
|
[ array
expression-list
]
|
|
|
[ set
expression-list
]
|
|
|
[ struct
[
(
:
|
=
)
expression
,
]
assignment-list
]
|
|
|
[ class
[
(
:
|
=
)
expression
,
]
assignment-list
]
|
|
|
[ module
[
(
:
|
=
)
expression
,
]
statement...
]
|
|
|
[ func
function-body
]
|
involve three further constructs, the expression-list, which is a comma separated list of expressions; the assignment-list, which is a comma separated list of assignments; and the function-body, which is the argument list and code body of a function. The syntax of the first of these is:
|
expression-list
|
empty
|
|
|
expression [
,
]
|
|
|
expression
,
expression-list
|
The expression-list is fairly simple. The construct empty is used to indicate that the whole list may be absent. Notice the optional comma after the last expression. This is designed to allow a more consistent formatting when the elements are line based, and simpler output from programmatically produced code. For example:
[array
"This is the first element",
"This is the second element",
"This is the third element",
]
The assignment list has similar features:
|
assignment-list
|
empty
|
|
|
assignment
[
,
]
|
|
|
assignment
,
assignment-list
|
|
|
|
|
assignment
|
struct-key
|
|
|
struct-key
=
expression
|
|
|
struct-key function-body
|
|
|
|
|
struct-key
|
identifier
|
|
|
(
expression
)
|
Each assignment is either an assignment to a simple identifier or an assignment to a full expression in brackets. The assignment to an identifier is merely a notational abbreviation for an assignment to a string. The following two struct literals are equivalent:
[struct abc = 4]
[struct ("abc") = 4]
The syntax of a function-body is:
|
function-body
|
(
identifier-list
)
compound-statement
|
|
|
|
|
identifier-list
|
empty
|
|
|
identifier
[
,
]
|
|
|
identifier
,
identifier-list
|
That is, an identifier-list is an optional comma separated list of identifiers with an optional trailing comma. Literal functions are rare in most programs; functions are normally named and defined with a special declaration form which will be seen in more detail below. The following two code fragments are equivalent; the first is the abbreviated notation:
static fred(a, b){return a + b;}
and:
static fred = [func (a, b){return a + b;}];
The meaning of functions will be discussed in more detail below.
Aggregates in general, and literal aggregates in particular, are fully nestable:
[array
[struct a = 1, c = 2],
[set "a", 1.2, 3],
"a string",
]
Note that aggregate literals are entirely evaluated by the parser. That is, each expression is evaluated and reduced to a particular value, these values are then used to build an object of the required type. For example:
[struct a = sin(0.5), b = cos(0.5)]
Causes the functions sin and cos to be called during the parsing process and the result assigned to the keys a and b in the struct being constructed. It is possible to refer to variables which may be in existence while such a literal is being parsed.
This ends our consideration of the lowest level element of an expression, the factor.
User defined literal factors
User defined literal factors, which have the form:
provide a mechanism for user supplied code to gain control of the parse-stream in order to interpret a custom syntax and return, presumably, a custom data item. The identifier is interpreted as a variable and its value determined (auto-loading extension modules as necessary). The value is used to determine a parser function. If the value is callable, it is the parser function, else it is indexed by the string parser to find the parser function.
In any case, the parser function is called with a single argument, being a special file object layerd on top of the interpreter's internal parser. Any normal file reading functions may be used to read this file (such as getchar(), gettoken() and others), as well as a set of special functions that use the interpreters internal lexical analyser and parser. These functions are parsetoken(), and parservalue(), and the associated functions rejecttoken(), rejectchar() and tokenobj(). They are described in detail in the chapter on core language functions. After reading the user data, the user parser function must leave the parse stream ready to read the closing square bracket token, and return the object that represents the literal value.
By using either raw character-level reading (with getchar and ilk), token oriented reading (with parsetoken), or whole expression level reading (with parsevalue) the user code can interpret either a completely custom syntax, a sytax built from the pre-exiting token types, a syntax that includes arbitrary expressions, or some combination thereof.
For example, consider a function to interpret a complex number literal:
static
cmplx(f)
{
c := struct();
c.r := parsevalue(f);
if (parsetoken(f) != ",")
fail("comma expected");
c.i := parsevalue(f);
return c;
}
After defining this function we can use literals such as:
x = [cmplx 3.0 + 1, 2];
Primary operators
A simple factor may be adorned with a sequence of primary-operations to form a primary-expression. That is:
|
primary-expression
|
factor
primary-operation...
|
|
|
|
|
primary-operation
|
[
expression
]
|
|
|
index-operator
identifier
|
|
|
index-operator
(
expression
)
|
|
|
|
|
index-operator
|
Any of:
|
|
|
. -> : :^
|
The first primary-operation (above) we have already seen. It is the operation of "indexing" which can be applied to aggregate types. For example, if xxx is an array:
xxx[10]
refers to the element of xxx at index 10. The parser does not impose any type restrictions (because typing is dynamic), although numerous type restrictions apply at execution time (for instance, arrays may only be indexed by integers, and floating point numbers are not able to be indexed at all).
Of the other index operators, . identifier, is a notational abbreviation of [ "identifier" ] , as seen previously. The bracketed form is again just a notational variation. Thus the following are all equivalent:
xxx["aaa"]
xxx.aaa
xxx.("aaa")
And the following are also equivalent to each other:
xxx[1 + 2]
xxx.(1 + 2)
Note that factors may be suffixed by any number of primary-operations. The only restriction is that the types must be right during execution. Thus:
xxx[123].aaa[10]
is legal.
The two constructs
|
|
->
identifier
|
|
|
-> (
expression
)
|
are again notational variations. In general, constructs of the form:
|
|
primary-expression
->
identifier
|
|
|
primary-expression
-> (
expression
)
|
are re-written as:
|
|
( *
primary-expresion
) .
identifier
|
|
|
( *
primary-expression
) . (
expression
)
|
The unary operator * used here is the indirection operator, its meaning is discussed later.
The index operators
:
and
:^
index the primary expression to discover a function -- the result of the operation is a callable method. These operators and methods are discussed in more detail below.
The last of the primary-operations:
is the call operation. Although, as usual, no type checking is performed by the parser; at execution time the thing it is applied to must be callable (for example, a function or method object). For example:
my_function(1, 2, "a string")
and
xxx.array_of_funcs[10]()
are both function calls. Function calls will be discussed in more detail below.
This concludes the examination of a primary-expression.
Terms
Primary-expressions are combined with prefix and postfix unary operators to make terms:
|
term
|
[
prefix-operator... ]
primary-expression
[
postfix-operator...
]
|
|
|
|
|
prefix-operator
|
Any of:
|
|
|
* & - + ! ~ ++ -- @ $
|
|
|
|
|
postfix-operator
|
Any of:
|
|
|
++ --
|
That is, a term is a primary-expression surrounded on both sides by any number of prefix and postfix operators. Postfix operators bind more tightly than prefix operators. Both types bind right-to-left when concatenated together. That is: -!x is the same as -(!x). As in all expression compilation, no type checking is performed by the parser, because types are an execution-time consideration.
Some of these operators touch on subjects not yet explained and so will be dealt with in detail in later sections. But in summary:
Prefix operators
|
*
|
Indirection; applied to a pointer, gives target of the pointer.
|
|
&
|
Address of; applied to any lvalue, gives a pointer to it.
|
|
-
|
Negation; gives negative of any arithmetic value.
|
|
+
|
Positive; no real effect.
|
|
!
|
Logical not; applied to 0 or NULL, gives 1, else gives 0.
|
|
~
|
Bit-wise complement.
|
|
++
|
Pre-increment; increments an lvalue and gives new value.
|
|
--
|
Pre-decrement; decrements an lvalue and gives new value.
|
|
@
|
Atomic form of; gives the (unique) read-only version of any value.
|
|
$
|
Immediate evaluation; see below.
|
Postfix operators
|
++
|
Post-increment; increments an lvalue and gives old value.
|
|
--
|
Post-increment; decrements an lvalue and gives old value.
|
One of these operators, $, is only a pseudo-operator. It actually has its effect entirely at parse time. The $ operator causes its subject expression to be evaluated immediately by the parser and the result of that evaluation substituted in its place. This is used to speed later execution, to protect against later scope or variable changes, and to construct constant values which are better made with running code than literal constants. For example, an expression involving the square root of two could be written as:
x = y + 1.414213562373095;
Or it could be written more clearly, and with less chance of error, as:
x = y + sqrt(2.0);
But this construct will call the square root function each time the expression is evaluated. If the expression is written as:
x = y + $sqrt(2.0);
The square root function will be called just once, by the parser, and will be equivalent to the first form.
When the parser evaluates the subject of a $ operator it recursively invokes the execution engine to perform the evaluation. As a result there is no restriction on the activity which can be performed by the subject expression. It may reference variables, call functions or even read files. But it is important to remember that it is called at parse time. Any variables referenced will be immediately interrogated for their current value. Automatic variables of any expression which is contained in a function will not be available, because the function itself has not yet been invoked; in fact it is clearly not yet even fully parsed.
The $ operator as used above increased speed and readability. Another common use is to avoid later re-definitions of a variable. For instance:
($printf)("Hello world\n");
Will use the printf function which was defined at the time the statement was parsed, even if it is latter re-defined to be some other function. It is also slightly faster, but the difference is small when only a simple variable look-up is involved. Notice the bracketing which has been used to bind the $ to the word printf. Function calls are primary operations so the $ would have otherwise referred to the whole function call as it did in the first example.
This concludes our examination of a term (remember that the full meaning of other prefix and postfix operators will be discussed in later sections).
Binary operators
We will now turn to the top level of expressions where terms are combined with binary operators:
|
expression
|
term
|
|
|
expression infix-operator expression
|
|
infix-operator
|
Any of:
|
|
|
@
|
|
|
* / %
|
|
|
+ -
|
|
|
>> <<
|
|
|
< > <= >=
|
|
|
== != ~ !~ ~~ ~~~
|
|
|
&
|
|
|
^
|
|
|
|
|
|
|
&&
|
|
|
||
|
|
|
:
|
|
|
?
|
|
|
= += -= *= /= %= >>= <<= &= ^= |= ~~= <=>
|
|
|
,
|
That is, an expression can be a simple term, or two expressions separated by an infix-operator. The ambiguity amongst expressions built from several binary-operator separated expressions is resolved by assigning each operator a precedence and also applying rules for order of binding amongst equal precedence levels. The lines of binary operators in the syntax rules above summarise their precedence. Operators on higher lines have higher precedence than those on lower lines. Thus 1+2*3 is the same as 1+(2*3). Operators which share a line have the same precedence. All operators except those on the second last line group left-to-right. Those on the second last line (the assignment operators) group right-to-left. Thus
a * b / c
is the same as:
(a * b) / c
But:
a = b += c
is the same as:
a = (b += c)
As with unary operators, the full meaning of each will be discussed in a later section. But in summary:
Binary operator summary
|
|
@
|
Form pointer
|
|
|
*
|
Multiplication, Set intersection
|
|
|
/
|
Division
|
|
|
%
|
Modulus
|
|
|
+
|
Addition, Set union
|
|
|
-
|
Subtraction, Set difference
|
|
|
>>
|
Right shift (shift to lower significance)
|
|
|
<<
|
Left shift (shift to higher significance)
|
|
|
<
|
Logical test for less than, Proper subset
|
|
|
>
|
Logical test for greater than, Proper superset
|
|
|
<=
|
Logical test for less than or equal to, Subset
|
|
|
>=
|
Logical test for greater than or equal to, Superset
|
|
|
==
|
Logical test for equality
|
|
|
!=
|
Logical test for inequality
|
|
|
~
|
Logical test for regular expression match
|
|
|
!~
|
Logical test for regular expression non-match
|
|
|
~~
|
Regular expression sub-string extraction
|
|
|
~~~
|
Regular expression multiple sub-string extraction
|
|
|
&
|
Bit-wise and
|
|
|
^
|
Bit-wise exclusive or
|
|
|
|
|
Bit-wise or
|
|
|
&&
|
Logical and
|
|
|
||
|
Logical or
|
|
|
:
|
Choice separator (must be right hand subject of ? operator)
|
|
|
?
|
Choice (right hand expression must use : operator)
|
|
|
=
|
Assignment
|
|
|
+=
|
Add to
|
|
|
-=
|
Subtract from
|
|
|
*=
|
Multiply by
|
|
|
/=
|
Divide by
|
|
|
%=
|
Modulus by
|
|
|
>>=
|
Right shift by
|
|
|
<<=
|
Left shift by
|
|
|
&=
|
And by
|
|
|
^=
|
Exclusive or by
|
|
|
|=
|
Or by
|
|
|
~~=
|
Replace by regular expression extraction
|
|
|
<=>
|
Swap values
|
|
|
,
|
Multiple expression separator
|
This concludes our consideration of expressions.
Statements
We will now move on to each of the executable statement types in turn.
Simple expression statements
The simple expression statement:
Is just an expression followed by a semicolon. The parser translates this expression to its executable form. Upon execution the expression is evaluated and the result discarded. Typically the expression will have some side-effect such as assignment, or make a function call which has a side-effect, but there is no explicit requirement that it do so. Typical expression statements are:
printf("Hello world.\n");
x = y + z;
++i;
Note that an expression statement which could have no side-effects other than producing an error may be completely discarded and have no code generated for it.
Compound statements
The compound statement has the form:
That is, a compound statement is a series of any number of statements surrounded by curly braces. Apart from causing all the sub-statements within the compound statement to be treated as a syntactic unit, it has no effect. Thus:
printf("Line 1\n");
{
printf("Line 2\n");
printf("Line 3\n");
}
printf("Line 4\n");
When run, will produce:
Line 1
Line 2
Line 3
Line 4
Note that the parser will not return control to the execution engine until all of a top-level compound statement has been parsed. This is true in general for all other statement types.
The if statement
The if statement has two forms:
|
|
if (
expression
)
statement
|
|
|
if (
expression
)
statement
else
statement
|
The parser converts both to an internal form. Upon execution, the expression is evaluated. If the expression evaluates to anything other than 0 (integer zero) or NULL, the following statement is executed; otherwise it is not. In the first form this is all that happens, in the second form, if the expression evaluated to 0 or NULL the statement following the else is executed; otherwise it is not.
The interpretation of both 0 and NULL as false, and anything else as true, is common to all logical operations in ICI. There is no special boolean type.
The ambiguity introduced by multiple if statements with an lesser number of else clauses is resolved by binding else clauses with their closest possible if. Thus:
if (a) if (b) dox(); else doy();
If equivalent to:
if (a)
{
if (b)
dox();
else
doy();
}
The while statement
The while statement has the form:
|
|
while
(
expression
)
statement
|
The parser converts it to an internal form. Upon execution a loop is established. Within the loop the expression is evaluated, and if it is false (0 or NULL) the loop is terminated and flow of control continues after the while statement. But if the expression evaluates to true (not 0 and not NULL) the statement is executed and then flow of control moves back to the start of the loop where the test is performed again (although other statements, as seen below, can be used to modify this natural flow of control).
The do-while statement
The do-while statement has the following form:
|
|
do statement while ( expression ) ;
|
The parser converts it to an internal form. Upon execution a loop is established. Within the loop the statement is executed. Then the expression is evaluated and if it evaluates to true, flow of control resumes at the start of the loop. Otherwise the loop is terminated and flow of control resumes after the do-while statement.
The for statement
The for statement has the form:
for ( [ expression ]; [ expression ]; [ expression ] ) statement
The parser converts it to an internal form. Upon execution the first expression is evaluated (if present). Then, a loop is established. Within the loop: If the second expression is present, it is evaluated and if it is false the loop is terminated. Next the statement is executed. Finally, the third expression is evaluated (if present) and flow of control resumes at the start of the loop. For example:
for (i = 0; i < 4; ++i)
printf("Line %d\n", i);
When run will produce:
Line 0
Line 1
Line 2
Line 3
The forall statement
The forall statement has the form:
forall ( expression [ ,expression ] in expression ) statement
The parser converts it to an internal form. In doing so the first and second expressions are required to be lvalues (that is, capable of being assigned to). Upon execution the first expression is evaluated and that storage location is noted. If the second expression is present the same is done for it. The third expression is then evaluated and the result noted; it must evaluate to an array, a set, a struct, a string, or NULL; we will call this the aggregate. If this is NULL, the forall statement is finished and flow of control continues after the statement; otherwise, a loop is established.
Within the loop, an element is selected from the noted aggregate. The value of that element is assigned to the location given by the first expression. If the second expression was present, it is assigned the key used to access that element. Then the statement is executed. Finally, flow of control resumes at the start of the loop.
Each arrival at the start of the loop will select a different element from the aggregate. If no as yet unselected elements are left, the loop terminates. The order of selection is predictable for arrays and strings, namely first to last. But for structs and sets it is unpredictable. Also, while changing the values of the structure members is acceptable, adding or deleting keys, or adding or deleting set elements during the loop will have an unpredictable effect on the progress of the loop.
As an example:
forall (colour in [array "red", "green", "blue"])
printf("%s\n", colour);
when run will produce:
red
green
blue
And:
forall (value, key in [struct a = 1, b = 2, c = 3])
printf("%s = %d\n", key, value);
when run will produce (possibly in some other order):
c = 3
a = 1
b = 2
Note in particular the interpretation of the value and key for a set. For consistency with the access method and the behavior of structs and arrays, the values are all 1 and the elements are regarded as the keys, thus:
forall (value, key in [set "a", "b", "c"])
printf("%s = %d\n", key, value);
when run will produce:
c = 1
a = 1
b = 1
But as a special case, when the second expression is omitted, the first is set to each "key" in turn, that is, the elements of the set. Thus:
forall (element in [set "a", "b", "c"])
printf("%s\n", element);
when run will produce:
c
a
b
When a forall loop is applied to a string (which is not a true aggregate), the "sub-elements" will be successive one character sub-strings.
Note that although the sequence of choice of elements from a set or struct is at first examination unpredictable, it will be the same in a second forall loop applied without the structure or set being modified in the interim.
The switch, case, and default statements
These statements have the forms:
switch ( expression ) compound-statement
case expression :
default :
The parser converts the switch statement to an internal form. As it is parsing the compound statement, it notes any case and default statements it finds at the top level of the compound statement. When a case statement is parsed the expression is evaluated immediately by the parser. As noted previously for parser evaluated expressions, it may perform arbitrary actions, but it is important to be aware that it is resolved to a particular value just once by the parser. As the case and default statements are seen their position and the associated expressions are noted in a table.
Upon execution, the switch statement's expression is evaluated. This value is looked up in the table created by the parser. If a matching case statement is found, flow of control immediately moves to immediately after that case statement. If there is a default statement, flow of control immediately moves to just after that. If there is no matching case and no default statement, flow of control continues just after the entire switch statement.
For example:
switch ("a string")
{
case "another string":
printf("Not this one.\n");
case 2:
printf("Not this one either.\n");
case "a string":
printf("This one.\n");
default:
printf("And this one too.\n");
}
When run will produce:
This one.
And this one too.
Note that the case and default statements, apart from the part they play in the construction of the look-up table, do not influence the executable code of the compound statement. Notice that once flow of control had transferred to the third case statement above, it continued through the default statement as if it had not been present. This behavior can be modified by the break statement described below.
It should be noted that the "match" used to look-up the switch expression against the case expressions is the same as that used for structure element look-up. That is, to match, the switch expression must evaluate to the same object as the case expression. The meaning of this will be made clear in a later section.
The break and continue statements
The break and continue statements have the form:
break ;
continue ;
The parser converts these to an internal form. Upon execution of a break statement the execution engine will cause the nearest enclosing loop (a while, do, for or forall) or switch statement within the same scope to terminate. Flow of control will resume immediately after the affected statement. Note that a break statement without a surrounding loop or switch in the same function or module is illegal.
Upon execution of a continue statement the execution engine will cause the nearest enclosing loop to move to the next iteration. For while and do loops this means the test. For for loops it means the step, then the test. For forall loops it means the next element of the aggregate.
The return statement
The return statement has the form:
return [ expression ] ;
The parser converts this to an internal form. Upon execution, the execution engine evaluates the expression if it is present. If it is not, the value NULL is substituted. Then the current function terminates with that value as its apparent value in any expression it is embedded in. It is an error for there to be no enclosing function.
The try statement
The try statement has the form:
try statement onerror statement
The parser converts this to an internal form. Upon execution, the first statement is executed. If this statement executes normally flow continues after the try statement; the second statement is ignored. But if an error occurs during the execution of the first statement control is passed immediately to the second statement.
Note that "during the execution" applies to any depth of function calls, even to other modules or the parsing of sub-modules. When an error occurs both the parser and execution engine unwind as necessary until an error catcher (that is, a try statement) is found.
Errors can occur almost anywhere and for a variety of reasons. They can be explicitly generated with the fail function (described below), they can be generated as a side-effect of execution (such as division by zero), and they can be generated by the parser due to syntax or semantic errors in the parsed source. For whatever reason an error is generated, a message (a string) is always associated with it.
When any otherwise uncaught error occurs during the execution of the first statement, two things are done:
-
Firstly, the string associated with the failure is assigned to the variable error. The assignment is made as if by a simple assignment statement within the scope of the try statement.
-
Secondly, flow of control is passed to the statement following the onerror keyword.
Once the second statement finishes execution, flow of control continues as if the whole try statement had executed normally.
For example:
static
div(a, b)
{
try
return a / b;
onerror
return 0;
}
printf("4 / 2 = %d\n", div(4, 2));
printf("4 / 0 = %d\n", div(4, 0));
When run will print:
4 / 2 = 2
4 / 0 = 0
The handling of errors which are not caught by any try statement is implementation dependent. A typical action is to prepend the file and line number on which the error occurred to the error string, print this, and exit.
The critsect statement
The critsect, or "critical section", statement has the form:
critsect statement
The parser converts this to an internal form. Upon execution, the statement is executed indivisibly with respect to other threads. Thus:
critsect x = x + 1;
will increment x by 1, even if another thread is doing similar increments. Without the use of the critsect statement we could encounter a situation where both threads read the current value of x (say 2) at the same time, then both added 1 and stored the result 3, rather than one thread incrementing the value to 3, then the other to 4.
The indivisibility bestowed by a critsect statement applies as long as the code it dominates is executing, including all functions that code calls. Even operations that block (such as the waitfor statement) will be affected. The indivisibility will be revoked once the critsect statement completes, either through completing normally, or through an error being thrown by the code it is dominating.
The waitfor statement
The waitfor statement has the form:
waitfor ( expression ; expression ) statement
The parser converts this to an internal form. Upon execution, a critical section is established that extends for the entire scope of the waitfor statement (except for the special exception explained below). Within the scope of this critical section, the waitfor statement repeatedly evaluates the first expression until it is true (that is, neither 0 nor NULL). Once the first expression evaluates to true, control passes to the statement (still within the scope of the critical section). After executing statement the critical section is released and the waitfor statement is finished.
However, each time the first expression evalutes to a false value, the second expression is evaluated and the object that it evaluates to is noted. Then, indivisibly, the current thread sleeps waiting for that object to be signaled (by a call to the wakeup() function), and the critical section is suppressed (thus allowing other thread to run). The thread will remain asleep until it is woken up by a call to wakeup() with the given object as an argument. Each time this occurs, the critical section is again enforced and the process repeats with the evaluation and testing of the first expression. While the thread is asleep it consumes no significant CPU time.
The waitfor statement is the basic method of inter-thread communication and control in ICI. It is typically used to gate control of some data that is passing from one thread to another. For example, suppose jobs is an array that is shared between two processes. In one thread we might write:
waitfor (nels(jobs) > 0; jobs)
job = rpop(jobs);
/*
* Process job...
*/
While in a second thread that is generating jobs we might write:
push(jobs, new_job);
wakeup(jobs);
In this example, the list object jobs is the object we are using to wait on and wakeup, but any object can be used. One technique is to use a commonly agreed string (strings being intrinsically atomic, will naturally be the same object without any explicit commonality between the threads). In some circumstances it may be necessary to apply a critsect to the access to the shared data (jobs in this example) in the thread doing the waking up.
It is very important to only perform the call to wakeup() after the condition that allows release of the wait has been established. To illustrate, suppose we had written:
wakeup(jobs); /* WRONG */
enqueue(jobs, new_job); /* WRONG */
In this case the waiting thread may have run between the two statements, evaluated the test to false, and gone to sleep again, possibly never to wake.
Similarly, the waitfor condition must be a true reflection of a condition that implies a wakeup will occur, at some stage, on the object being waited on. Do not assume that because the thread has woken up, the wakeup has been for the expected reason. For example, it would be wrong to write:
wait_once = 0;
waitfor (wait_once++; jobs) /* WRONG */
jobs = dequeue(jobs);
The null statement
The null statement has the form:
;
The parser may convert this to an internal form. Upon execution it will do nothing.
Declaration statements
There are two types of declaration statements:
declaration storage-class declaration-list ;
storage-class identifier function-body
storage-class extern
static
auto
The first is the general case while the second is an abbreviated form for function definitions. Declaration statements are syntactically equal to any other statement, but their effect is made entirely at parse time. They act as null statements to the execution engine. There are no restriction on where they may occur, but their effect is a by-product of their parsing, not of any execution.
Declaration statements must start with one of the storage-class keywords listed above. Considering the general case first, we next have a declaration-list.
declaration-list identifier [ = expression ]
declaration-list , identifier [ =
expression ]
That is, a comma separated list of identifiers, each with an optional initialisation, terminated by a semicolon. For example:
static a, b = 2, c = [array 1, 2, 3];
The storage class keyword establishes which scope the variables in the list are established in, as discussed earlier. Note that declaring the same identifier at different scope levels is permissible and that they are different variables.
A declaration with no initialisation first checks if the variable already exists at the given scope. If it does, it is left unmodified. In particular, any value it currently has is undisturbed. If it does not exist it is established and is given the value NULL.
A declaration with an initialisation establishes the variable in the given scope and gives it the given value even if it already exists and even if it has some other value.
Note that initial values are parser evaluated expressions. That is they are evaluated immediately by the parser, but may take arbitrary actions apart from that. For example:
static
fibonacci(n)
{
if (n <= 1)
return 1;
return fibonacci(n - 1) + fibonacci(n - 2);
}
static fib10 = fibonacci(10);
The declaration of fib10 calls a function. But that function has already been defined so this will work.
Note that the scope of a static variable is (normally) the entire module it is parsed in. For example:
static
func()
{
static aStatic = "The value of a static.";
}
printf("%s\n", aStatic);
when run will print:
The value of a static.
That is, despite being declared within a function, the declaration of aStatic has the same effect as if it had been declared outside the function. Also notice that the function has not been called. The act of parsing the function caused the declaration to take effect.
The behavior of extern variables has already been discussed, that is, they are declared as static in the parent module. The behavior of auto variables, and in particular their initialisation, will be discussed in a later section.
Abbreviated function declarations
As seen above there are two forms of declaration. The second:
storage-class identifier function-body
is a shorthand for:
storage-class identifier = [ func function-body ] ;
and is the normal way to declare simple functions. Examples of this have been seen above.
Functions
As with most ICI constructs there are two parts to understanding functions; how they are parsed and how they execute.
When a function is parsed four things are noted:
-
the names and positions of the formal parameters;
-
the names and initialisation of auto variables;
-
the static scope or class in which the function is declared;
-
the code generated by the statements in the function.
The formal parameters (that is, the identifiers in the bracket enclosed list just before the compound statement) are actually implicit auto variable declarations. Each of the identifiers is declared as an auto variable without an initialisation, but in addition, its name and position in the list is noted.
Upon execution (that is, upon a function call), the following takes place:
-
The auto variables, as noted by the parser, along with any initialisations, are copied as a group. This copy forms the auto variables of this invocation.
-
Any actual parameters (that is, expressions provided by the caller) are matched positionally with the formal parameter names, and the value of those expressions are assigned to the auto variables of those names.
-
If there were more actual parameters than formal parameters, and there is an auto variable called vargs, the remaining argument values are formed into an array which is assigned to vargs.
-
If this is a method call (see below) the auto variable this is set to the subject object of the call, and the auto variable class is set to the class (if any).
-
The variable-scope is set such that the auto variables are the inner-most scope.
-
Successive outer scopes are set to the static scope, or, if this is a method call, the class noted when the function was parsed.
-
The flow of control is diverted to the code generated by parsing the function.
A return statement executed within the function will cause the function to return to the caller and act as though its value were the expression given in the return statement. If no expression was given in the return statement, or if execution fell through the bottom of the function, the apparent return value is NULL. In any event, upon return the scope is restored to that of the caller. All internal references to the group of automatic variables are lost (although as will be seen later explicit program references may cause them to remain active).
Simple functions have been seen in earlier examples. We will now consider further issues.
It is very important to note that the parser generates a prototype set of auto variables which are copied, along with their initial values, when the function is called. The value which an auto variable is initialised with is a parser evaluated expression just like any other initialisation. It is not evaluated on function entry. But on function entry the value the parser determined is used to initialise the variable. For example:
static myVar = 100;
static
myFunc()
{
auto anAuto = myVar;
printf("%d\n", anAuto);
anAuto = 500;
}
myFunc();
myVar = 200;
myFunc();
When run will print:
100
100
Notice that the initial value of anAuto was computed just once, changing myVar before the second call did not affect it. Also note that changing anAuto during the function did not affect its subsequent re-initialisation on the next invocation.
As stated above, formal parameters are actually uninitialised auto variables. Because of the behaviour of variable declarations it is possible to explicitly declare an auto variable as well as include it in the formal parameter list. In addition, such an explicit declaration may have an initialisation. In this case, the explicit initialisation will be effective when there is no actual parameter to override it. For example:
static
print(msg, file)
{
auto file = stdout; /* Default value. */
fprintf(file, "%s\n", msg);
}
print("Hello world");
print("Hello world", stderr);
In the first call to the function print there is no second actual parameter. In this case the explicit initialisation of the auto variable file (which is the second formal parameter) will have its effect unmolested. But in the second call to print a second argument is given. In this case this value will over-write the explicit initialisation given to the argument and cause the output to go to stderr.
As indicated above there is a mechanism to capture additional actual parameters which were not mentioned in the formal parameter list. Consider the following example:
static
sum()
{
auto vargs;
auto total = 0;
auto arg;
forall (arg in vargs)
total += arg;
return total;
}
printf("1+2+3 = %d\n", sum(1, 2, 3));
printf("1+2+3+4 = %d\n", sum(1, 2, 3, 4));
Which when run will produce:
1+2+3 = 6
1+2+3+4 = 10
In this example the unmatched actual parameters were formed into an array and assigned to the auto variable vargs, a name which is recognised specially by the function call mechanism.
And also consider the following example where a default initialisation to vargs is made. In the following example the function call is used to invoke a function with an array of actual parameters, the function array is used to form an array at run-time, and addition is used to concatenate arrays; all these features will be further explained in later sections:
static
debug(fmt)
{
auto fmt = "Reached here.\n";
auto vargs = [array];
call(fprintf, array(stderr, fmt) + vargs);
}
debug();
debug("Done that.\n");
debug("Result = %d, total = %d.\n", 123, 456);
When run will print:
Reached here.
Done that.
Result = 123, total = 456.
In the first call to debug no arguments are given and both explicit initialisations take effect. In the second call the first argument is given, but the initialisation of vargs still takes effect. But in the third call there are unmatched actual parameters, so these are formed into an array and assigned to vargs, overriding its explicit initialisation.
Objects
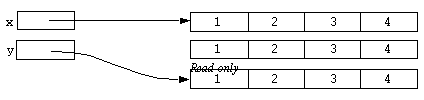
Up till now few exact statements about the nature of values and data have been made. We will now examine values in more detail. Consider the following code fragment:
static x;
static y;
x = [array 1, 2, 3, 4];
y = x;
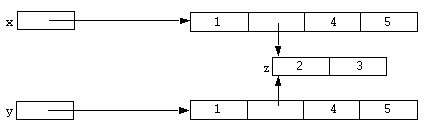
After execution of this code the variable x refers to an array. The assignment of x to y causes y to refer to the same array. Diagrammatically:
If the assignment:
y[1] = 200;
is performed, the result is:
We say that x and y refer to the same object. Now consider the following code fragment:
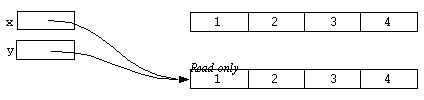
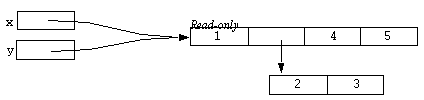
static x;
static y;
x = [array 1, 2, 3, 4];
y = [array 1, 2, 3, 4];
Diagrammatically:
In this case, x and y refer to different objects, despite that fact they are equal.
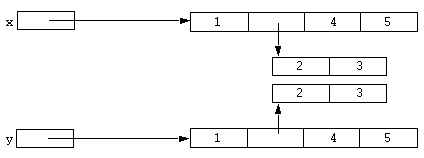
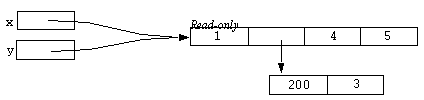
Now consider one of the unary operators which was only briefly mentioned in the sections above. The @ operator returns a read-only version of the sub-expression it is applied to. Consider the following statement:
y = @y;
After this has been executed the result could be represented diagrammatically as:
The middle array now has no reference to it and the memory associated with it will be collected by the interpreter's standard garbage collection mechanism. Now consider the following statement:
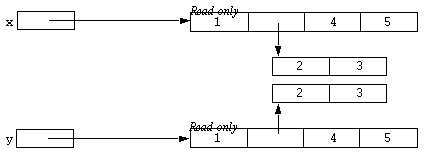
x = @x;
This is similar to the previous statement, except that this time x is replaced by a read-only version of its old value. But the result of this operation is:
Notice that x now refers to the same read-only array that y refers to. This is a fundamental property of the @ operator. It returns the unique read-only version of its argument value. Such read-only objects are referred to as atomic objects. The array which x used to refer to was non-atomic, but the array it refers to now is an atomic array. Aggregate types such as arrays, sets and structs are generally non-atomic, but atomic versions can be obtained (as seen above). But most other types, such as integers, floats, and (normally) strings are intrinsically atomic. That is, no matter how a number, say 10, is generated, it will be the same object as every other number 10 in the interpreter. For-instance, consider the following example:
x = "ab" + "cdefg";
y = "abcde" + "fg";
After this is executed the situation can be represented diagrammatically as:
It is important to understand when objects are the same object, when they are different and the effects this has.
Equality
We saw above how two apparently identical arrays were each distinct objects. But these two arrays were equal in the sense of the equality testing operator ==. If two values are the same object they are said to be eq, and there is a function of that name to test for this condition. Two objects are equal (that is ==) if:
-
they are the same object (i.e. eq); or
-
they are both arithmetic (int and float) and have equivalent numeric values; or
-
they are aggregates of the same type and all the sub-elements are the same objects (i.e. eq).
This definition of equality is the basis for resolving the merging of aggregates into unique read-only (atomic) versions. Two aggregates will resolve to the same atomic object if they are equal. That is, they must contain exactly the same objects as sub-elements, not just equal objects. For example:
static x = [array 1, [array 2, 3], 4, 5];
static y = [array 1, [array 2, 3], 4, 5];
Could be represented diagrammatically as:
Now, if the following statements were executed:
x = @x;
y = @y;
The result could be represented diagrammatically as:
That is, both x and y refer to new read-only objects, but they refer to different read-only objects because they have an element which is not the same object. The simple integers are the same objects because integers are intrinsically atomic objects. But the two sub-arrays are distinct objects. Being equal was not sufficient. The top-level arrays needed to have exactly the same objects as contents to make x and y end up referring to the same read-only array. In contrast to this consider the following similar situation:
static z = [array 2, 3];
static x = [array 1, z, 4, 5];
static y = [array 1, z, 4, 5];
This could be represented diagrammatically as:
Now, if the following statements were executed:
x = @x;
y = @y;
The result could be represented diagrammatically as:
In this case both x and y refer to the same read-only array because the original arrays where equal, that is, all their elements were the same objects. Notice that one of the elements is still a writeable array. The read-only property is only referring to the top level array. The sub-array can be changed, but the reference to it from the top level array can not. Thus:
x[1][0] = 200;
will result in:
whereas the statement:
x[1] = 200;
will just result in an error.
Structure and set keys
Any object, not just a string, can be used as a key in a structure. For instance:
static x = [struct];
static z = [array 10, 11];
x["abc"] = 1;
x[56] = 2;
x[z] = 3;
Could be represented diagrammatically as:
And the assignment:
x[z] = 300;
would replace the 3 in the above diagram with 300. But the assignment:
x[[array 10, 11]] = 300;
would result in a new element being added to the structure because the array given in the above statement is a different object from the one which z refers to.
Similarly, elements of sets may be any objects.
Indexing structures by complex aggregates is as efficient as indexing by intrinsically atomic types such as strings and integers.
Structure super types
Up till now structures have been described as simple lookup tables which map a key, or index, to a value. But a structure may have associated with it a super structure.
The function super can be used to discover the current super of a struct and to set a new super. With just one argument it returns the current super of that struct, with a second argument it also replaces the super by that value.
When a key is being looked-up in a structure for reading, and it is not found and there is a super struct, the key is further looked for in the super struct, if it is found there its value from that struct is returned. If it is not found it will be looked for in the next super struct etc. If no structures in the super chain contain the key, the special value NULL is returned.
When a key is being looked up in a structure for writing, it will similarly be searched for in the super chain. If it is found in a writeable structure the value in the structure in which it was found will be set to the new value. If it was never found, it will be added along with the given value to the very first struct, that is, the structure at the base, or root, of the super chain.
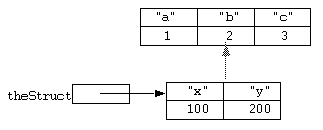
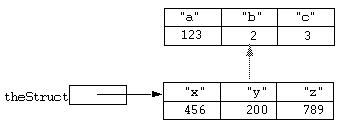
Consider the following example:
static theSuper = [struct a = 1, b = 2, c = 3];
static theStruct = [struct x = 100, y = 200];
super(theStruct, theSuper);
After this statement the situation could be represented diagrammatically as:
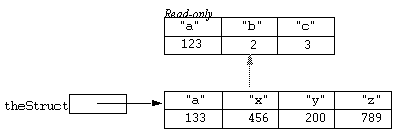
then if the following statements were executed:
theStruct.a = 123;
theStruct.x = 456;
theStruct.z = 789;
the situation could be diagrammatically represented as:
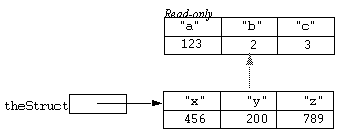
If a super struct is not writeable (that is, it is atomic) values will not be written in it and will lodge in the base structure instead. Thus consider what happens if we replace the super structure in the previous example by its read-only version:
super(theStruct, @theSuper);
The situation could now be represented diagrammatically as:
If the assignment statement:
theStruct.a += 10;
were executed, the value of the element a will first be read from the super structure, this value will then have ten added to it, and the result will be written back into the base structure; because the super structure is read-only and cannot be modified. The finally situation can be represented diagrammatically as:
Note that many structs may share the same super struct. Thus a single read-only super struct can be used hold initial values; saving explicit initialisations and storage space.
The function assign may be used to set a value in a struct explicitly, without reference to any super structs; and the function fetch may be used to read a value from a struct explicitly, without reference to any super structs.
Within a struct-literal a colon prefixed expression after the struct identifier is used as the super struct. For example, the declarations used in the previous example could be written as:
static theSuper = [struct a = 1, b = 2, c = 3];
static theStruct = [struct:theSuper, x = 100, y = 200];
An aside on variables and scope
Now that structs and their super have been described a more precise statement about variables and scope can be made.
ICI variables are entries in ordinary structs. At all times, the execution context holds a reference to a struct that is the current scope for the lookup of simple variables. An un-adorned identifier in an expression is just an implicit reference to an element of the current scope structure. The inheritance and name hiding of the variable scope mechanism is a product of the super chain.
During both module parsing and function execution, the auto variables are the entries in the base structure. The super of this is the struct containing the static variables. The next super struct contains the externs, and successive super structs are successive outer scopes.
Auto, static and extern declarations make explicit assignments to the appropriate structure.
The function scope can be used to obtain the current scope structure; and to set it (use with care).
But there is a difference in the handling of undefined entries. Whereas normal lookup of undefined entries in a structure produces a default value of NULL, the implicit lookup of undefined variables triggers an attempt to dynamically load a library to define the variable (see Undefined variables and dynamic loading below), and failing that, produce an error ("%s undefined").
Base types
ICI supports a base set of standard data types. Each is identified by a simple name. In summary these are:
-
array
-
An ordered sequence of objects.
-
exec
-
A thread execution context.
-
file
-
An open file reference.
-
float
-
A double precision floating point number.
-
func
-
A function.
-
int
-
A signed 32 bit integer.
-
list
-
An ordered set of objects.
-
mem
-
References to raw machine memory.
-
method
-
A binding of a function and a subject object.
-
ptr
-
A reference to a storage location.
-
regexp
-
A compiled regular expression.
-
set
-
An unordered collection of objects.
-
string
-
An ordered sequence of 8 bit characters.
-
struct
-
An unordered set of mappings from one object to another.
Many of these base types have been alluded to in previous sections. The following sections describe each type in more detail.
It should be noted that indexing and calling are the only operations that are an intrinsic property of each base type. Other behaviours of base types are a product of operators and functions that perform their various functions when supplied with operands of particular types. For this reason the following descriptions typically describe what data an instance of each base type holds, what happens when it is indexed or called, and may briefly mention the functions and operators that are highly relevant to the type. See following sections on operators and core functions for a complete picture.
In the following text, the word "efficient" typically means in constant time or memory, although occasional internal housekeeping may occur.
array - An ordered sequence of objects
An array is a contiguous (in memory) block of object references. The first object is referred to with index zero, subsequent elements of the block are referenced by successive integers. The index must always be an integer, else the indexing operation will fail. Reading at indicies not in the block results in a NULL value. Writing at negative indicies fails, while writing at indicies beyond the current end of the block silently extends the block, and NULL fills the span between the old end and the newly written element. The function nels() can be used to reveal the number of elements currently in the array (which is also the index of the first element beyond the current length of the array).
Arrays offer the most memory-efficient method of storing collections of objects. The functions push(), pop(), rpush(), rpop() and top() are of note. They allow arrays to be used as efficient stacks and queues. They are all of constant order time. Most other functions and operations on arrays are O(n). For example, array addition is O(n + m) where n and m are the lengths of the two arrays.
The rpush() and rpop() functions push and pop items from the front of the array (that is, near index zero). But the first item is always considered to be at index zero. Pushing and popping items on the front of an array effectively changes the index of all the items in the array.
See also the functions array() to create an array at run-time, and the parse-time in-line literal form of arrays [array ...]. The function sort() can be used to sort the elements of an array.
ICI arrays form the fundamental basis for operand, execution and scope stacks in the ICI internal execution engine, as well as the storage of compiled code. Although the latter is not visible to the ICI programmer.
exec - A thread execution context
An exec object holds the execution context for a thread of exection and is returned by the thread() function.
Exec objects can be indexed by:
-
status
-
Which yields a string, either "active", "finished" or "failed".
-
result
-
Before the thread has finished, this field reads as NULL. Once, or if, the top level function returns, this field yields the value returned from that function. If the thread failed with an uncaught error, accessing the result field will cause the thread accessing it to inherit that error as if it had just occured.
file - An open file reference
A file object is a reference and interface to some lower level file-like object. Most commonly a real file supported by the operating system, but not necessarilly so. The actual file object holds a reference to the basic file object, and references to its primitive access methods and operations. Those primitive methods are directly represented by the intrinsic ICI functions: close(), eof(), flush(), getchar(), put(), and seek(). In addition, the functions getline(), getfile(), gettoken(), and gettokens() efficiently build on these to read higher level constructs than simple bytes from a file. These functions can greatly increase the efficiency of file parsing over explicit per-character operations. The function printf() provides efficient formatted output to files.
File objects are generally created by "open" functions; such as the archetypal fopen() function that opens or creates a host operating system file. Also note the sopen() function that allows an ICI string object to be opened as a file. The variables stdin, stdout, and stderr are generally created in the outer-most scope at interpreter startup and refer to the associated files of the current process. Also, various functions, such as printf(), will, if no explicit file argument is supplied, use the current value of the appropriate variable. These functions do this by looking up the name in the current scope, so it is possible to locally override their default file usage.
Files can not be indexed or called.
Note that an unreferenced file object will, eventually, be collected by the ICI interpreter's garbage collector, at which point it will be closed (if it is not already closed). But the indeterminate timming of garbage collections makes it inadvisable to rely on this mechanism to close files. In general, files should be explicitly closed to release lower level resources at a deterministic time. A file object is still a valid object after it has been closed, except no I/O operations will work on it any more.
(There is currently a paucity of functions to support reading and writing binary files. This will be corrected in future revisions. The sys extension module does provide some support. TML)
float - A double precision floating point number
A float holds a double precision floating point number (in the local machine's native format). Floats are intrinsically atomic, based on their value (that is, all floats with a particular value are references to the same memory location). Floats can not be indexed or called and their utility is entirely based on the operators and functions that accept and return them.
func - A function
A function holds a reference to executable code, and a name suitable for diagnostics. In reality there are two types of function objects: functions that reference native machine code, and functions that reference interpreted ICI code. But they are both called "func".
Function objects that link to interpreted ICI code also hold the names of the formal parameters and a prototype of the local scope structure that will be copied and used each time the function is invoked.
Function objects are intrinsically atomic based on the identity of all their components. The ICI parser also makes code atomic so in theory equal functions will be identical objects, but in practice such items as source file line information embedded in executable code frustrate this.
Function objects can, of course, be called. The semantics of this operation has been described above. Function objects are also the basis of methods in classes, the difference merely existing in their preparation by the parser, and the semantics of calling through a method.
Function objects can be indexed by some specific names to discover some of the internal elements. Specifically:
-
name
-
Returns a name that has been assigned to the function. In the case of the "abbreviated function declaration" described above, it will be the identifier associated with the function. In the case of an in-line function literal, it will be the name _funcname_. In the case of a function implemented in native machine code, it will be an author assigned name.
-
autos
-
Returns the (atomic) prototype auto scope struct of this function, or NULL for functions implemented in native machine code. The super of this struct reveals the static scope of this function (the parsed class for a method).
-
args
-
Returns the (atomic) array of formal parameter names, or NULL for functions implemented in native machine code.
int - A signed 32 bit integer
An int hold a 32 bit signd integer (in the local machine's native format). Ints are intrinsically atomic based on their value (that is, all ints with a particular value are references to the same memory location). Ints can not be indexed or called and their utility is entirely based on the operators and functions that accept and return them.
mem - A reference to raw machine memory
A mem object references byte- or word-structured native machine memory. The mem object holds the base address of a region of raw machine memory, the word-size it is to be accessed with (1, 2 or 4 bytes per word), and the number of words that can be accessed.
The base address identifies the first word, and this can be accessed (as an integer) at index zero. Successive integers indicies reference successive words, up to the limit. Reading outside the bounds returns NULL, writing outside the bounds causes an error. Words are read and written in the native machine format (endieness in particular). One and two byte words are read as unsigned quantities. When writing, non-zero bits above the word size are simply discarded.
Mem objects can be used for simple, but dense, unstructured data storage. But they are most commonly used in interfaces to native machine code or hardware. The functions mem() and alloc() can be used to create mem objects. Although mem(), which allows access to arbitrary native machine addresses, may be disallowed in some systems. The function alloc() allocates memory for the mem object to refer to which is freed when the mem object is garbage collected.
Mem objects are intrinsically atomic, based on the address, word size and number of elements.
method - A binding of a function and a subject object
A method holds a reference to a callable object, and a subject object. The subject object is typically a struct of some class (that is, its super is the class). The callable object is typically a function of the class or one of its super classes.
Method objects can be called, the semantics of which are described above.
Method objects can be indexed to discover their internal elements. Specifically:
-
subject
-
Returns the subject object of the method. This is typically a struct.
-
callable
-
Returns the callable object of the method. This is typically a function.
Method objects are created by the : operator, typically preparatory to the invocation of a class function. But in most situations the parser will generate a special type of shortcut function invocation to avoid the run-time creation of an ephemeral method object. So in practice method objects are quiet rare.
ptr - A reference to a storage location
Pointers are references to storage locations. Storage locations are the elements of anything which can be indexed. That is, array elements, set elements, struct elements and others. Variables (which are just struct elements) can be pointed to.
Pointers hold two objects, one is the object pointed into, the other is the key used to access the location in question.
The & operator is used to obtain a pointer to a location. Thus if the following were executed:
static x;
static y = [array 1, 2, 3];
static p1 = &x;
static p2 = &y[1];
The variable p1 would be a pointer to x and the variable p2 would be a pointer to the second element of y. Reference to the object a pointer points to can be obtained with the * operator. Thus if the following were executed:
*p1 = 123;
*p2 = 456;
printf("x = %d, y[1] = %d\n", x, y[1]);
the output would be:
x = 123, y[1] = 456
The generation of a pointer does not affect the location being pointed to. In fact the location may not even exist yet. When a pointer is referenced the same operation takes place as if the location was referenced explicitly. Thus a search down the super chain of a struct may occur, or an array may be extended to include the index being written to, etc.
In addition to simple indirection (that is the * operator), pointers may be indexed. But the index values must be an integer, and the key stored as part of the pointer must also be an integer. When a pointer is indexed, the index is added to the key which is stored as part of the pointer, the sum forms the actual index to use when referencing the aggregate recorded by the pointer. For instance, continuing the example above:
p2[1] = 789;
would set the last element of the array to 789, because the pointer currently references element 1, and the given index is 1, and 1 + 1 is 2 which is the last element. The index arithmetic provided by pointers will work with any types, as long as the indicies are integers, thus:
static s = [struct (20) = 1, (30) = 2, (40) = 3];
static p = &s[30];
p[-10] = -1;
p[0] = -2;
p[10] = -3;
Would replace each of the elements in the struct s by their negative value.
Pointers can be called, but this is an obsolete facility and may be removed in future versions.
regexp - A compiled regular expression
A regexp object holds a regular expression and its compiled form. Regular expressions describe text patterns against which actual text can be matched to discover if the actual text matches the pattern. They can also be used to extract sub-strings of the actual text based on the pattern matching. For more details on the syntax and semantics of regular expressions, see the chapter on the subject below.
Regular expressions are created by the regexp() and regexpi() functions, and by the parser from regular expression literals (that is, #...#). Text can be matched against regular expressions by the operators ~, !~, ~~, and ~~~, and by the functions sub(), gsub() and smash().
Regular expressions can be indexed by two specific names:
-
pattern
-
Returns the original pattern as a string.
-
option
-
Returns an integer bit mask of the options applied in making the regular expression.
Regular expressions are intrinsically atomic, based on the identity of the original pattern.
set - An unordered collection of objects
A set is an unordered collection of object references. Any single object can either be in a given set, or not in the set. It can not be in the set multiple times. Adding and removing objects from sets is an efficient constant time operation, and each distinct object in the set imposes a small fixed memory cost (both access speed and memory cost is slightly higher than the per element cost of an array). The type and complexity of an object being added or removed from a set has no effect on the efficiency of the operation.
Sets can be used in different ways. In some circumstances they are used simply as unordered aggregates of other objects. In other circumstances they are used more as algebraic sets to record which objects have a certain property. In this regard they can be particularly useful because objects can be noted as having a particular property without modifying the internals of the object at all.
string - An ordered sequence of 8 bit characters
A string holds an ordered sequence of 8 bit characters. Almost all string operations produce atomic (read-only) strings (that is, all strings with a particular value are references to the same memory location). Strings can be indexed by an int (read only) to reveal a one-character sub-string, or an empty string if negative or beyond the end of the string. Most of the utility of strings derive from the functions and operators that can be applied to them.
Strings are one of the commonest structure keys. Variables are identified by strings (there is no separate "name" or "variable" type in ICI).
Non-atomic (i.e. mutable) strings can be produced by the strbuf() function, and extended with the strcat() function. Integer character codes can be assigned to particular characters of non-atomic strings by integer (base 0) index. Assigning to a character beyond the end of the string will extend the string as necessary with space filling. Note that a mutable string is a distinct object from an atomic versions of equal value, and so doesn't access the same element when used as a struct index.
struct - An unordered set of mappings
A struct is an unordered set of mappings. That is, a struct records object references that are regarded as keys and for each such key, a corresponding value, which is also an object reference. A struct also records a super struct, which is a reference to a subsequent struct. The details of structure indexing are described above. See Structure and set keys.
Structures form the fundamental basis for variables and scoping in ICI.
Adding, removing and looking up objects in a struct is an efficient constant time operation (although is O(n) with respect to searches up the super chain). The type and complexity of an object being added or removed from a set has no effect on the efficiency of the operation.
 Expressions
Expressions